As
there was no previous research which documented students' mathematical
language systematically, a methodology needed to be developed for
collecting and analysing the data. In setting up this probe study,
one of our original research questions had been: What is an effective
method for analysing children's talk about mathematics? This chapter,
therefore, sets out our decision making process in regard to choosing
a methodology. Some of the decisions which would affect what we
could say about students' language choices were: how much data was
to be collected; from what students; interacting in which situations.
As well, how we chose to interrogate the data would have an impact
on the type of model of student language that could be described.
Reviewing the
literature suggested that we were likely to find differences between
groups of students. Variables such as gender, age and socioeconomic
background can be considered as socially constructed, with language
use being one of the ways that individuals are positioned within
a society (Wodak & Benke, 1997). In doing this research, it was
important to recognise that specific features could not be considered
as 'male' or 'female' but rather if there were differences these
would occur along a continuum, as 'linguistic differences are very
often a matter of probabilities and tendencies' (Laver & Trugill,
1979, p. 23). As we were uncertain how differences in linguistic
choices would manifest themselves, the data had to be analysed flexibly
enough so that interesting things could be identified. As a quantitative
approach to research requires the researcher to know what they are
investigating before they begin, it was felt that a qualitative
approach would be more appropriate. Qualitative research has been
described as having the following 5 characteristics (Bogdan & Biklen,
1982, p. 27-30): |
| |
1.
|
Qualitative
research has the natural setting as the direct source of data and
the researcher is the key instrument |
| |
2.
|
Qualitative
research is descriptive |
| |
3.
|
Qualitative
researchers are concerned with process rather than simply with outcomes
or products |
| |
4.
|
Qualitative
researchers tend to analyze their data inductively |
| |
5.
|
Meaning
is of essential concern to the qualitative approach |
| |
|
|
|
|
| However,
as we wanted to produce a description of students' language, we anticipated
that there would be particular features that required counting and
so we did not discount the need to use some statistical techniques
in our analysis. This combination of techniques from both approaches
is not uncommon in research on language in educational settings (Swann,
1994). However, any combination of techniques results in compromises
and some of the decisions made about the research and the related
compromises are outlined below. |
| |
|
|
|
|
| aData
Collection |
In
data collection, there were several issues which needed to be considered.
These included: in what setting should the data be gathered; from
whom should it be gathered; and by whom. The decisions about these
would have an impact on the description of students' language that
we would be able to produce. Qualitative research suggests the need
for natural settings from which to gather data as context has an
important effect on the production of linguistic data. Halliday
(Halliday & Hasan, 1985) described the context of situation as being
made up of what is going on, who is taking part and what role the
language is playing. Changes to any of these affect perceptions
of the context which then affect the language choices seen as appropriate.
For example, how the teacher is perceived as interacting with students
will influence students' language choices (see Khisty and Chval,
2002). For a robust model of student language to be developed from
this research, it was important to keep the situation as similar
as possible for all students. Yet there was a need for a variety
of students to participate so that we were not relying on one or
two students to provide a representative sample.
Studies into
the language used by students in mathematics classrooms have, in
general, only had a small number of participants. This has probably
been because transcribing audiotapes of interactions takes large
amounts of time (Swann, 1994) and produces huge amounts of data
(Milroy, 1987 p. 22). Occasionally, studies on language in mathematics
education have been done with larger numbers of participants (Rowland,
2000, Bills & Gray, 2001 and Bills, 2002). As part of his study,
Rowland (2000) interviewed 230 students in one primary school to
investigate their use of hedges. To do this he used a standardised
set of questions and each interview took only five to ten minutes.
The study by Bills (2002 and Bills & Gray, 2001) used 80 students
who were interviewed at various times over two years. The transcribed
interviews were then analysed to find the linguistic characteristics
which accompanied correct calculations. Such studies constrained
the language choices of students because they responded to a series
of questions provided by an interviewer rather than being allowed
more control over what was discussed (Rowland, 2000). However, the
situations can be manipulated so that they are similar for every
student and it was for this benefit that we decided to use data
from the National Education Monitoring Project (NEMP). In NEMP,
several hundred, randomly selected students in Year 4 and Year 8
from throughout New Zealand respond to the same set of tasks which
are asked by about 100 teacher administrators (Flockton & Crooks,
1997 and Crooks & Flockton, 2001). The responses that the students
give provide a snapshot each four years of what these students know
in mathematics. Many of these tasks are video recorded and, therefore,
can be transcribed relatively easily.
Interviewing
students for NEMP is not the same as recording naturally occurring
interactions in classrooms. However, the interactions between the
students and the teacher administrators were similar to interactions
that students would be expected to have with their own classroom
teachers. Milroy (1987 p. 41), in discussing the collection of data
for descriptive linguistic studies, stated that '[f]rom the interviewee's
point of view, a co-operative response is often one which is maximally
brief and relevant'. This could also describe the expected discourse
patterns in teacher/child interactions in classrooms, except that
the teacher administrators are told not to provide feedback on the
correctness of the student's response, even though the provision
of feedback is a typical part of classroom discourse (see Edwards
& Mercer, 13 1987). With NEMP assessments, the students work with
the same pair of teacher administrators over the course of a week
and so have some opportunity to interact before doing the mathematics
tasks. We were aware that the interviewer's age, gender, ethnicity
and personality could affect the language choice of students (Bogdan
& Biklen, 1982). On the whole, the teacher administrators -mostly
female from middle-class backgrounds- would be similar to the teachers
that students were likely to have in their own classrooms. Therefore,
we hoped that many students would respond in the same way with the
teacher administrators as they would with their classroom teachers
and so would use language which closely resembled what they would
use in their own classrooms. The students did the tasks in their
own schools although not in their own classrooms. NEMP assessment
is considered low stakes as it has no impact on the child's academic
programme nor is it directly linked to school performance (Crooks
& Flockton, 2001). Using the NEMP material was a compromise, as
it allowed us to gather material from a large number of students
where the style and set of questions were the same for all. Although
it was not a classroom setting, the data was gathered in a context
which was familiar to students. However, the decision to collect
this data meant that we would be unable to comment on student-student
interactions or even how students would use mathematics language
when they had more control over the direction of the interview.
A main advantage
of NEMP was that it was possible to choose students who fitted particular
demographic descriptions such as gender, age (Year 4 or Year 8)
and the decile ranking of the school attended. It is generally accepted
in New Zealand that the decile ratings for schools relate to the
socio-economic background of students (Bicknell, 1999). There are,
of course, difficulties with such a categorisation as it is fraught
with issues over who is making the decisions and what constitutes
the factors which are relevant to such a decision (see Robinson,
1979). However, with few alternatives available, a decision was
made to accept the common belief that children who came from high
decile schools were from more affluent backgrounds. Tasks were also
available whose responses could be related to the ethnicity of the
students. These interested us as there had been studies to show
that Pacific students living in New Zealand do not achieve as well
as their European or Asian peers (Young- Loveridge, 2000) and so
we wanted to know whether ethnicity was reflected in the language
choices of students. As a result, videotapes of students were chosen
based not only on gender and age, but also on their attendance at
particular decile-rated schools and whether they were Pacific Islanders
or not. |
| |
|
|
|
|
| aTasks
Selected for Analysis |
To
produce a rich description of students' mathematical explanations
and justifications, it was necessary to look at responses to more
than one task. This would enable us to see how the task as part
of the context affected the language choices of students and so
give us more insight into the process of making those choices. We,
therefore, transcribed videos of children responding to four different
tasks. From tasks done in 1997, we selected 'Better Buy' and 'Weigh
Up' (see Flockton and Crooks, 1997) and 'Motorway' and 'Bank Account'
from 2001 (see Crooks and Flockton, 2001). These tasks are provided
in the Figures below. Instructions for the teacher administrator
are given in bold. |
|
|
|
|
|
| |
| Better
Buy |
| Place
the 100g and 50 g boxes of Pebbles in front
of the student. |
| In
this activity you will be using some boxes of Pebbles.
The big box holds 100 grams of Pebbles and
costs $1.30. The smaller box holds 50 grams of Pebbles
and costs 60 cents. |
| 1. |
Which
one is better value for money? |
| Prompt:
Which box would give you more Pebbles for the
money? |
| 2.
|
Why
is that box better value for money? |
| 3. |
How
do you know that? |
|
Place the 20g box of Pebbles in front of the
student. |
| 4. |
This
box costs 30 cents. Which is the better buy - this 20g
box or this 100g? |
| Point
to the 20 g box. |
| 5. |
If
I wanted 100 g of Pebbles, how many of these
boxes would I need? |
| 6. |
How did you work that out? |
|
|
Figure
2.1: Instructions for teacher administrators for the Better Buy
Task. |
| Weigh
up |
| 1. |
Here
are four boxes of Pebbles. They look the same, but they
each have a different weight or mass. Think about how
you could put them in order from the lightest to the
heaviest - then tell me how you would do it using the
balance. Don't use the balance yet. |
| |
If
the student simply says "Weigh them"... |
| |
How
would they go about weighing them? |
| |
Put
the placement mat in front of the student. |
| 2. |
I want you to use this balance to help you work out
the order of the objects, from the lightest to the heaviest.
Tell me how you are working it out as you are doing
it and put the boxes in order on the placement mat. |
| |
Once
the student has arranged the boxes in order from lightest
to heaviest, record their decisions on the recording
sheet. |
| 3. |
If
you had to explain to someone else in your class how
to work out the order from lightest to heaviest, what
would you tell them to do? |
|
|
Figure
2.2: Instructions for teacher administrators for the Weigh Up Task |
| Motorway |
| Motorway
Show student photo. |
| This
picture shows a busy motorway. During the day time,
about 98 cars go down this road every minute. |
| 1.
|
About
how many cars would go down the road in 9 minutes? |
| 2. |
Explain
to me how you got your answer. |
|
|
Figure
2.3: Instructions for teacher administrators for the Motorway Task.
|
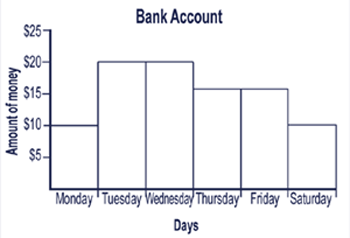
| Bank
Account |
|
Put
graph and ruler in front of student. |
| |
This
graph shows someone's bank account. |
| |
Point
to the words amount of money. |
| |
Up
this side is the amount of money the person has. |
| |
Point
to the word days. |
| |
Along
the bottom are the days of a week. |
| |
Have
a careful look at the graph then tell me a story to
explain what is happening with the money. |
| |
Point
to the beginning of the graph. |
|
|
Figure
2.4: Instructions for teacher administrators for the Bank Account
Task. |
|
Figure
2.5: Bank Account Graph |
| |
|
|
|
|
The
two tasks from 1997 were done by the same set of students whereas
the ones from 2001 were done by separate groups. By using the 1997
tasks, we were thus able to see how the actual questions affected
the same students' responses. Bills and Grey's (2001) research had
compared students' use of linguistic features between mathematical
and non-mathematical explanations. This showed that students might
use certain linguistic features such as logical connectives in one
context but not in another one. This suggested that context had
an influence on the linguistic choices that students felt were appropriate.
By being able to compare the same students giving responses to two
mathematical tasks we would be able to see how much was related
to the student and how much was related to the task. Students attempting
the 1997 tasks could be chosen based on age, gender and decile rating
of school attended whereas students doing the 2001 tasks could also
be grouped according to ethnicity.
As can be seen
from the instructions for the tasks, Weigh Up and Motorway required
students to provide explanations of what they did whilst Better
Buy and Bank Account requested justifications. Better Buy required
students to justify their choice of boxes. This was often done by
students making reference to the calculation that they did. Bank
Account requested students tell a story about the Bank Account and
we had anticipated that students would justify why the amounts on
the graphs changed during the week. As the correctness of responses
varied for these tasks (Flockton & Crooks, 1997 and Crooks & Flockton,
2001), it can be considered that they were mathematically challenging.
In order to
develop a robust model of the language that children used in giving
mathematical explanations and justifications, we needed to ensure
that we had a large enough sample size. Many descriptive linguistic
studies used reasonably small samples. Labov's well-known generalisations
of the speech of New Yorkers was based on a sample size of only
88 speakers (Labov, 1966). Hawkins (1977) investigated the nominal
groups used by five-year olds in London. Having decided on his variables
of social class, IQ, gender and communication index of mothers (CI),
he formed a matrix of 2 x 3 x 2 x 2 cells and assigned 5 children
to each cell. However, as he did not have middle-class children
who had both low IQ and low CI, two of the cells remained empty
(one for boys and one for girls). This meant that he had a total
of 110 samples of five-year old children's talk to analyse. Hawkins
(1977) recommended using such a matrix by stating that '[i]ts advantage
is that the effects of each variable may be estimated independently'
(p. 8). Increasing the number of samples results in data handling
issues which could make the research impractical. |
| |
|
|
|
|
| aParticipants |
| It
was decided for this research that a matrix of the variables of interest
to us would be drawn up and we would seek to have six children allocated
to each cell. This is illustrated in Table 2.1, which shows the distribution
for the first two task transcripts, from 1997. For each of the four
tasks, we would have a total of 72 transcripts of different children's
mathematical language. |
| |
Table
2.1. Distribution of students chosen for analysis of Better
Buy and Weigh Up, with six students per cell. |
 |
| Year
|
High
Decile Schools |
Middle
Decile School |
Low
Decile School |
|
| 4 |
Girls |
Boys |
Girls |
Boys |
Girls |
Boys |
| 8 |
Girls |
Boys |
Girls |
Boys |
Girls |
Boys |
|
| |
|
|
|
|
| For
the Motorway and Better Buy tasks, the sample of students selected
was as shown in Table 2.2. These tasks, from the 2001 NEMP administration,
included an enlarged sample of students from Pasifika backgrounds
which we drew upon to examine whether or not there were any linguistic
differences in this sub-sample. |
| |
| Table
2.2. Distribution of students chosen for analysis of Motorway
and Better Buy, with six students per cell. |
|
| Year
|
High
Decile Schools |
Low
Decile Schools
non-Pasifika students |
Low
Decile Schools
Pasifika students |
|
| 4 |
Girls |
Boys |
Girls |
Boys |
Girls |
Boys |
| 8 |
Girls |
Boys |
Girls |
Boys |
Girls |
Boys |
|
| |
|
|
|
|
A
decision was made to include those students who remained mute when
asked a question as we felt that there may be patterns in their
distribution. This sampling method ensured that any group, such
as students from different decile schools, would contain at least
24 samples. This number increased when results across all four tasks
were compared. As the students doing the two 1997 tasks were the
same, our total sample size was 216. We anticipated that, with a
sample size of 216 students and 288 transcripts to interrogate,
patterns in linguistic choices would become apparent.
Although we
would have access to the videos of students, we had to limit what
we would analyse. Much information such as eye signals and gestures
is lost when transcriptions are made (Swann, 1994), but, in order
to keep the project manageable, it was decided that we would concentrate
on the linguistic expressions used by students. As a result, only
student responses were transcribed, as the NEMP procedure required
the teacher administrators to ask set questions. It soon became
apparent that this had not always happened, but by only having transcriptions
of the student responses, we were forced to concentrate on their
linguistic choices. However, it did mean that we missed opportunities
to discuss the interactions between students and the teacher administrators.
One final advantage
of using NEMP data was that ethics approval had already been granted.
Obtaining consent from students and their parents and other interested
parties such as the Ministry of Education is important in educational
research to ensure that participants, especially children, are not
exploited (Cameron, Frazer, Harvey, Rampton & Richardson, 1994).
Yet 'going through the formal procedures that some educational systems
require can be a long, laborious process' (Bogdan & Biklen, 1982,
p. 122) so it was useful to have this ethical approval already obtained.
Cameron et al. (1994) also raised the ethical issue of how the results
would be used which might be contrary to interests of the participants.
In doing research where differences between groups could be highlighted,
we needed to ensure that any findings were seen as important only
if they enabled teachers to better understand the mathematical learning
of students. It was not possible to discover this, however, until
we knew what some of these differences were.
This research
set out to develop a robust model of student language in giving
mathematical explanations and justifications. As a result, it was
felt that a qualitative approach was the most suitable in order
to achieve this. However, in determining how to implement such an
approach, compromises had to be made between the aims of being as
descriptive as possible, whilst also using naturalistic settings
and keeping the study manageable. |
| |
|
|
|
|
| aAnalysing
the Data |
Once
the decisions had been made about what data to collect, we then
had to consider how it was to be analysed. As we were unsure what
aspects of students' language were most useful in producing a robust
description, it was necessary to consider how others had approached
their analysis of students' mathematical language. For example,
Chapman (1997) examined her transcripts to discover the ways that
the teacher rephrased students' utterances and how these rephrasing
were then picked up by the students. In other studies such as that
by Gooding and Stacey (1993), transcripts were coded so that specific
types of responses (asking questions, responses to requests for
clarification) were highlighted and their use related to common
18 attributes of the groups of students who used them. For our research,
neither methods of analysis seemed appropriate as we were not focussing
on the exchanges between students and the teacher administrators;
rather we were comparing different students' responses.
We were also
aware of the potential difficulties associated with a coding system
which simply reflected what researchers expected to see (see Edwards,
1976) and how this did not support a qualitative approach to the
research to be undertaken. Originally, we started by looking for
particular features that we felt were more mathematical in student
responses, such as the use of nominalisations or noun phrases as
agents of actions rather than people, following the example of Hawkins
(1977). These features were based on work described in Meaney (forthcoming).
As reported
in Meaney and Irwin (2003), the results from this investigation
were confusing (these are given at the beginning of each task chapter).
We started again by classifying students' responses according to
the clarity of their language and their accuracy. We then discussed
what it was that contributed to some students' responses being classified
as clear.
It was at this
point that the work by Hasan (Halliday and Hasan, 1985) became valuable
in our search for tools with which to do the analysis. This was
because her beliefs about text structure enabled us to
code students' responses but in ways that supported the illumination
of patterns. It also enabled us to keep the context of the responses
as an integral part of the description. Hasan's (Halliday and Hasan
1985, p. 56) described contextual configuration as the significant
attributes of a social environment in which a text is constructed.
Contextual configuration can be used to predict the text structure.
In this study,
students' explanations were given in responding to questions on
a mathematics task asked by a teacher administrator in a school
environment. Hasan (Halliday and Hasan 1985) stated that the contextual
configuration 'can predict the OBLIGATORY and the OPTIONAL elements
of a text's structure as well as their SEQUENCE vis-á-vis
each other and the possibility of their ITERATION' (p. 56 capitals
and italics in original text). However, as Hasan also pointed out,
the relationship between language and situation is bi-directional
and some elements of the text structure will, in fact, help to construct
the situation. For example, when a student provided a minimal response
and the teacher administrator kept prompting, sometimes this probing
became more about teaching the student than about assessing their
current understanding. If these further questions become an obligatory
element of the situation, then the situation changed from one of
assessment to one of teaching.
By looking for
the patterns of obligatory and optional elements and how they are
sequenced and repeated across different students' responses, we
could describe different children's perceptions of the situation.
As there had been no previous work in this area, our coding was
inductive rather than looking for expected elements, thus we hoped
to limit the problems identified by Edwards (1976) in regard to
coding.
In order to
ensure reliability of results, all coding and counting was done
with at least one person doing the majority of the work and another
doing some checking. At times, the checking was done by research
assistants who were trained in what was 19 being counted or coded.
Occasionally, the Year 4 and Year 8 data were counted or coded separately
after initial joint coding or counting. There was some cross checking.
Discrepancies between counters and coders were discussed and clarified.
A qualitative analysis needs analytical tools which do not constrain
the data but which support the uncovering of patterns within it,
so that a rich description of students' language choices can be
made. Although we also began to look at the data through other lenses,
Hasan's ideas about contextual configuration enabled us to reveal
subtle differences in how groups of students constructed their justifications
and explanations in mathematics through combining text elements.
We are aware that this choice of analysis tools means that our description
of students' language choices will be limited to the existence and
ordering of elements within their texts. |
| |
|
|
|
|
| aSummary |
Our
research question was: What are the typical linguistic choices of
different groups of students when giving mathematical explanations
and justifications? In examining ways that it could be investigated,
we were aware that these would have an impact on what we would ultimately
be able to present as our findings. A quantitative approach might
have produced a more systematic description showing how often terms
and expressions were present in students' speech. Yet, it may not
have enabled the context in which the students' responses were made
to be an integral part of that description. We were aware that we
had compromised the requirement of a natural setting for our qualitative
data gathering. However, it would not have been possible to make
any comparisons between the language used by different groups if
the setting was not the same for all students. Our ultimate goal
was to contribute to teachers' understanding of how their perception
of students' knowledge about mathematics was affected by students'
choice of language. It seemed valuable to produce a model which
was as broad as possible and still placed importance on the context.
Yet we were also aware that by looking at student-student or student-teacher
interactions during learning experiences the model that we would
have been able to produce would have been significantly different.
To ensure that our study remained manageable we were forced to narrow
our research question and then chose data gathering and data analysis
methods which provided us with a robust model of students' language
in giving mathematical explanations and justifications.
The following
chapters provide information on each task. They begin by discussing
the 1997 tasks and then provide information on the 2001 tasks. These
chapters are then followed by further discussion on stories in mathematical
tasks and text structures of explanations and justifications. |
|